|
I am currently a postdoctoral researcher at Carnegie Mellon University in the Robotics Institute advised by Prof. Kris Kitani. Prior to that, I obtained my Ph.D. in Computer Science from Peking University, advised by Prof. Yizhou Wang. I obtained my M.S. and B.S. degrees from Peking University.
|

|
ResearchMy research interest lies at the intersection of computer vision, computer graphics, and machine learning. My long-term goal is to perceive and understand the dynamic 3D world, modeling humans, animals, and their environments in a physically grounded and high-fidelity way to enable meaningful reasoning and interaction.I am excited to lead a research project on animal behavior in collaboration with Prof. Yixin Zhu and Prof. Federico Rossano, who directs the Comparative Cognition Lab (CCL) at UCSD. I previously interned at Microsoft Research Asia (MSRA), working with Dr. Chunyu Wang. Selected projects3D human modeling: ContextPose, VirtualMarker, MotionBERT, VMarker-Pro, SAT-HMR, FreeCloth CV for animals: ChimpACT, AlphaChimp |
NewsJun. 2026: DeTRC is accepted by IJCV.Apr. 2026: AlphaChimp is accepted by IJCV. Feb. 2026: SingleTX-EISP is accepted as a Highlight at CVPR 2026. Jan. 2026: We are organizing 6th CV4Animals Workshop @CVPR 2026. Jul. 2025: I successfully defend my PhD. Feb. 2025: 2 papers accepted by CVPR 2025. Jan. 2025: We are organizing 5th CV4Animals Workshop @CVPR 2025. Jan. 2025: VMarker-Pro is accepted to IEEE TPAMI. |
|
Abstract |
Arxiv |
Code |
Project page |
Bibtex
Reconstructing dynamic non-rigid objects from monocular video requires integrating visual cues from direct observations with data-driven priors over geometry and appearance. Prior approaches either learn to directly predict 4D representations from visual input or initialize a 3D representation that is subsequently deformed and refined based on video evidence. However, the former are constrained by the scarcity of 4D training data, while the latter leverage priors only for the initial reconstruction and rely solely on video supervision thereafter; neither handles complex in-the-wild scenarios with large deformations and occlusions well. We present Lift4D, a test-time optimization framework that addresses both limitations. First, we adapt an existing single-view 3D reconstruction model to yield temporally consistent per-frame predictions via causal latent conditioning, providing a coherent initialization for a deformable 3D Gaussian Splatting representation. We then "sculpt" this representation to match the input video through an occlusion-aware optimization that faithfully recovers visible surface details while completing unobserved regions using a view-conditioned diffusion prior. We demonstrate that Lift4D clearly improves over prior 4D reconstruction methods, particularly on challenging in-the-wild sequences with severe occlusions and non-rigid motion.
|
|
|
Abstract |
Arxiv |
Code |
Project page |
Bibtex
Reconstructing physically stable 3D scenes from a single RGB image enables casual images to be converted into simulation-ready digital assets for applications such as immersive interaction and content creation. However, existing single-image reconstruction methods fall short in capturing the physical structure of a scene. As a result, they often produce geometrically plausible but physically inconsistent results, including object floating and penetration, which lead to unstable behavior in physics simulations. Image-conditioned scene generation methods improve physical plausibility but often rely on strong scene priors, yielding plausible yet inaccurate object arrangements that fail to match the input image. We propose REST3D, a single-image reconstruction framework that can REconstruct physically STable 3D scenes by integrating physical scene understanding with physics-constrained refinement. We first introduce an agentic physical scene understanding technique that constructs a scene-tree representation capturing object physical states and inter-object relationships from a gravity-support perspective, providing a structural prior for reconstruction. Leveraging this structure, we initialize the scene using image-to-3D models, followed by scene-tree-guided alignment and physics-constrained optimization to resolve physical violations while preserving visual consistency with the input image. Experiments show that our method significantly reduces physical errors and improves simulation stability on both synthetic and real-world datasets while maintaining strong reconstruction quality. We further demonstrate the reconstructed scenes in VR-based human-object interaction, showing their potential for immersive applications.
|
|
|
Abstract |
Arxiv |
Code |
Project page |
Bibtex
Digital human generation has been studied for decades and supports a wide range of real-world applications. However, most existing systems are passively animated, relying on privileged state or scripted control, which limits scalability to novel environments. We instead ask: how can digital humans actively behave using only visual observations and specified goals in novel scenes? Achieving this would enable populating any 3D environments with any digital humans, at scale, that exhibit spontaneous, natural, goal-directed behaviors. To this end, we introduce Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm that replicates humans at multiple levels: they look, perceive, reason, and behave like real people in real-world 3D scenes. The World Layer provides a structured substrate for interaction, by reconstructing semantically rich 3D Gaussian scenes from real-world videos via an occlusion-aware semantic scene reconstruction pipeline, and accommodating animatable Gaussian-based human avatars within them. The Agent Layer transforms these avatars into autonomous humanoid agents, equipping them with first-person RGB-D perception and enabling them to perform accurate, embodied planning with spatial-awareness and iterative reasoning, which is then executed at the low level as full-body actions to drive their behaviors in the scene. We further introduce a comprehensive benchmark to evaluate humanoid–scene interaction within diverse reconstructed 3D environments. Extensive experimental results demonstrate that our agents achieve robust autonomous behavior through effective planning and action execution, yielding higher task success rates and fewer collisions compared to both ablations and state-of-the-art planning methods. This work offers a new perspective on populating scenes with digital humans in an active manner, enabling more research opportunities for the community and fostering human-centric embodied AI. Data, code, and models will be open-sourced.
|
|

|
Abstract |
Arxiv |
Bibtex
Text-to-image (T2I) diffusion models have shown remarkable success in generating high-quality images from text prompts. Recent efforts extend these models to incorporate conditional images (e.g., canny edge) for fine-grained spatial control. Among them, feature injection methods have emerged as a training-free alternative to traditional fine-tuning-based approaches. However, they often suffer from structural misalignment, condition leakage, and visual artifacts, especially when the condition image diverges significantly from natural RGB distributions. Through an analysis of existing methods, we identify a key limitation: the sampling schedule of condition features, previously unexplored, fails to account for the evolving interplay between structure preservation and domain alignment throughout diffusion steps. Inspired by this observation, we propose a flexible training-free framework that decouples the sampling schedule of condition features from the denoising process, and systematically investigate the spectrum of feature injection schedules to achieve a better balance between structural alignment and appearance quality. We further enhance the sampling process by introducing a restart refinement schedule, and improve the visual quality with an appearance-rich prompting strategy. Together, these designs enable training-free controllable generation that is both structure-rich and appearance-rich. Extensive experiments demonstrate that our method achieves state-of-the-art performance under complex and diverse conditions. Owing to its generality, our framework naturally supports compositional conditional generation and generalizes across architectures in a plug-and-play manner, from UNet-based diffusion models to modern DiT backbones such as FLUX.
|



|
Abstract |
Paper |
Arxiv |
Code |
Project page |
Video |
Bibtex
Temporal repetition counting aims to quantify the repeated action cycles within a video. The majority of existing methods rely on the similarity correlation matrix to characterize the repetitiveness of actions, but their scalability is hindered due to the quadratic computational complexity. In this work, we introduce a novel approach that employs an action query representation to localize repeated action cycles with linear computational complexity. Based on this representation, we further develop two key components to tackle the fundamental challenges of temporal repetition counting. Firstly, to facilitate open-set action counting, we propose the dynamic action query. Unlike static action queries, this approach dynamically embeds video features into action queries, offering a more flexible and generalizable representation. Second, to distinguish between actions of interest and background noise actions, we incorporate inter-query contrastive learning to regularize the video feature representation corresponding to different action queries. As a result, our method significantly outperforms previous works, particularly in terms of long video sequences, unseen actions, and actions at various speeds. On the challenging benchmark RepCountA, we outperform the state-of-the-art method TransRAC by 26.5% in OBO accuracy, with a 22.7% mean error decrease and 94.1% computational burden reduction.
|
|
|
Abstract |
Paper |
Arxiv |
Code |
Project page |
Bibtex
Understanding non-human primate behavior is crucial for improving animal welfare, modeling social behavior, and gaining insights into both distinctly human and shared behaviors. Despite recent advances in computer vision, automated analysis of primate behavior remains challenging due to the complexity of their social interactions and the lack of specialized algorithms. Existing methods often struggle with the nuanced behaviors and frequent occlusions characteristic of primate social dynamics. This study aims to develop an effective method for automated detection, tracking, and recognition of chimpanzee behaviors in video footage. Here we show that our proposed method, AlphaChimp, an end-to-end approach that simultaneously detects chimpanzee positions and estimates behavior categories from videos, significantly outperforms existing methods in behavior recognition. AlphaChimp achieves approximately 10% higher tracking accuracy and a 20% improvement in behavior recognition compared to state-of-the-art methods, particularly excelling in the recognition of social behaviors. This superior performance stems from AlphaChimp's innovative architecture, which integrates temporal feature fusion with a Transformer-based self-attention mechanism, enabling more effective capture and interpretation of complex social interactions among chimpanzees. Our approach bridges the gap between computer vision and primatology, enhancing technical capabilities and deepening our understanding of primate communication and sociality. We release our code and models and hope this will facilitate future research in animal social dynamics. This work contributes to ethology, cognitive science, and artificial intelligence, offering new perspectives on social intelligence.
|
|
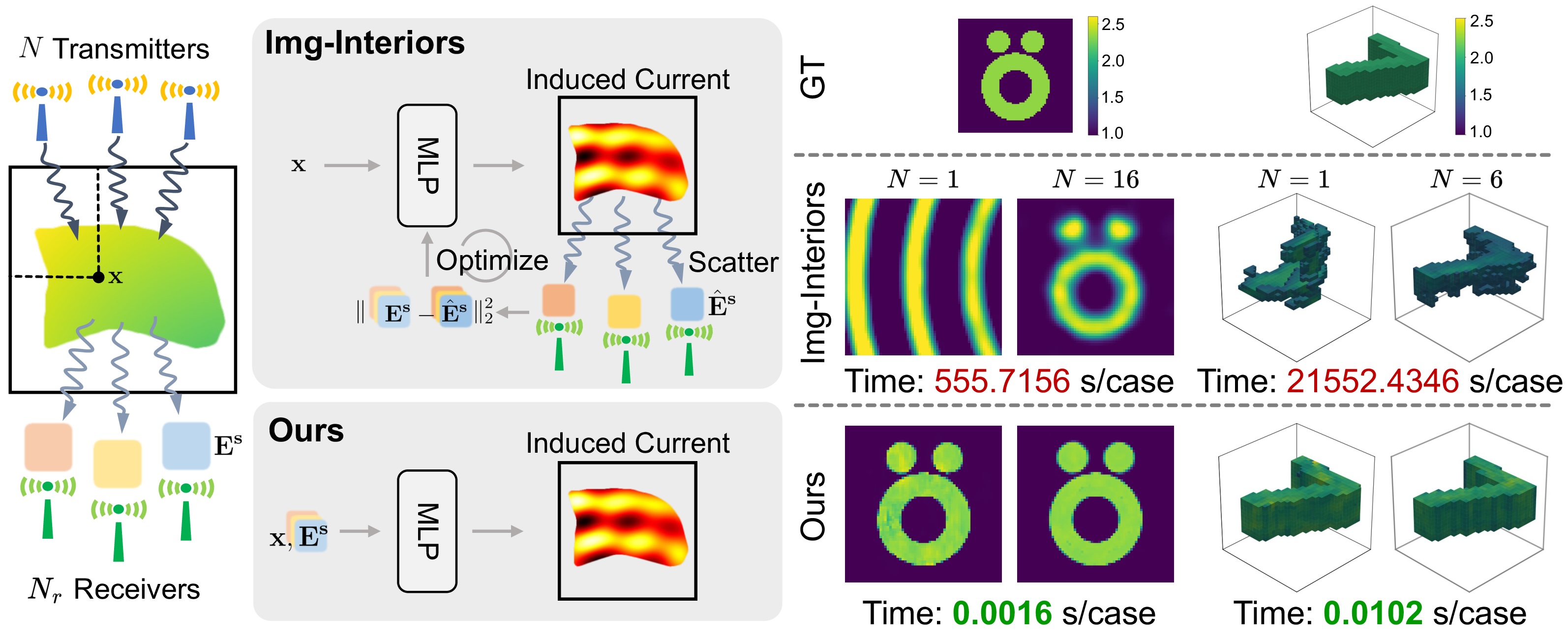
|
Abstract |
Paper |
Code |
Project page |
Video |
Bibtex
Solving Electromagnetic Inverse Scattering Problems (EISP) is fundamental in applications such as medical imaging, where the goal is to reconstruct the relative permittivity from scattered electromagnetic field. This inverse process is inherently ill-posed and highly nonlinear, making it particularly challenging, especially under sparse transmitter setups, e.g., with only one transmitter. A recent machine learning-based approach, Img-Interiors, shows promising results by leveraging continuous implicit functions. However, it requires time-consuming case-specific optimization and fails under sparse transmitter setups. To address these limitations, we revisit EISP from a data-driven perspective. The scarcity of transmitters leads to an insufficient amount of measured data, which fails to capture adequate physical information for stable inversion. Built on this insight, we propose a fully end-to-end and data-driven framework that predicts the relative permittivity of scatterers from measured fields, leveraging data distribution priors to compensate for the lack of physical information. This design enables data-driven training and feed-forward prediction of relative permittivity while maintaining strong robustness to transmitter sparsity. Extensive experiments show that our method outperforms state-of-the-art approaches in reconstruction accuracy and robustness. Notably, it achieves high-quality results even with a single transmitter, a setting where previous methods consistently fail. This work offers a fundamentally new perspective on electromagnetic inverse scattering and represents a major step toward cost-effective practical solutions for electromagnetic imaging.
|
|
Abstract |
Paper |
Code |
Project page |
Video |
Bibtex
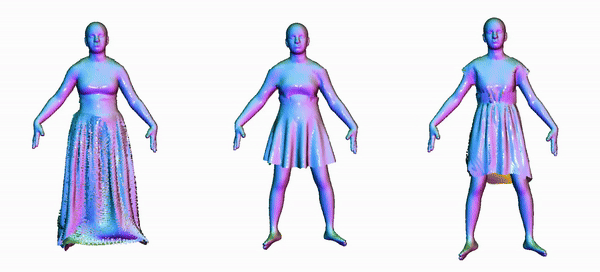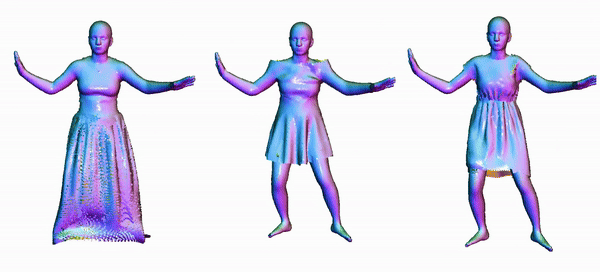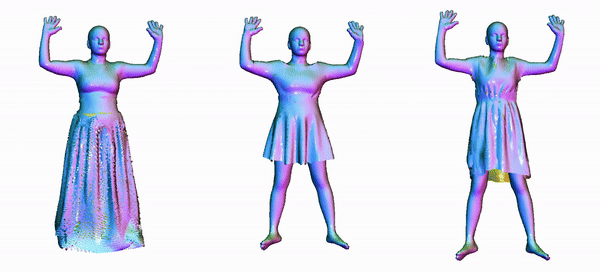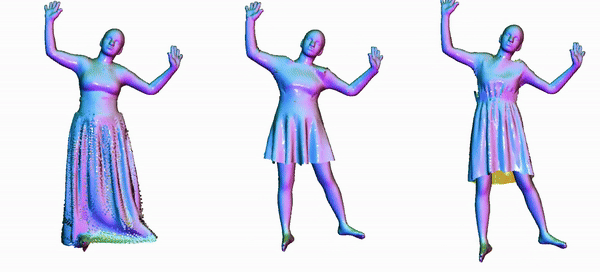
Animating 3D clothed humans requires the modeling of pose-dependent deformations in various poses. The diversity of clothing styles and body poses makes this task extremely challenging. Prior works rely on LBS skinning and predict local transformation in the canonical space. Nevertheless, it's quite challenging to model loose clothing, such as skirt and long dress, since they deviate significantly from the human body. Incorrect estimation of rigid transformations makes it difficult for the model to regress the residuals, which inevitably degrades the performance. In this work, we revisit the task of clothed humans modeling from a novel perspective. Our key insight is that canonicalization isn't a necessary step to predict clothing deformation, which circumvents the drawbacks of LBS posing in essence. Instead, we propose to learn features in the posed space. Without bell and whistle, our proposed model achieves state-of-the-arts performance on the CAPE and the ReSynth dataset. This simple yet effective paradigm provides a new possiblity of modeling pose-dependent deformation. Our model is capable of generating realistic 3D clothed humans with better perceptual quality.
|
|
Abstract |
Paper |
Code |
Project page |
Video |
Bibtex
We propose a one-stage framework for real-time multi-person 3D human mesh estimation from a single RGB image. While current one-stage methods, which follow a DETR-style pipeline, achieve state-of-the-art (SOTA) performance with high-resolution inputs, we observe that this particularly benefits the estimation of individuals in smaller scales of the image (e.g., those far from the camera), but at the cost of significantly increased computation overhead. To address this, we introduce scale-adaptive tokens that are dynamically adjusted based on the relative scale of each individual in the image within the DETR framework. Specifically, individuals in smaller scales are processed at higher resolutions, larger ones at lower resolutions, and background regions are further distilled. These scale-adaptive tokens more efficiently encode the image features, facilitating subsequent decoding to regress the human mesh, while allowing the model to allocate computational resources more effectively and focus on more challenging cases. Experiments show that our method preserves the accuracy benefits of high-resolution processing while substantially reducing computational cost, achieving real-time inference with performance comparable to SOTA methods.
|
|
|
Abstract |
Paper |
Code |
Bibtex
Monocular 3D human mesh estimation faces challenges due to depth ambiguity and the complexity of mapping images to complex parameter spaces. Recent methods propose to use 3D poses as a proxy representation, which often lose crucial body shape information, leading to mediocre performance. Conversely, advanced motion capture systems, though accurate, are impractical for markerless wild images. Addressing these limitations, we introduce an innovative intermediate representation as virtual markers, which are learned from large-scale mocap data, mimicking the effects of physical markers. Building upon virtual markers, we propose VirtualMarker, which detects virtual markers from wild images, and the intact mesh with realistic shapes can be obtained by simply interpolation from these markers. To address occlusions that obscure 3D virtual marker estimation, we further enhance our method with VMarker-Pro, a probabilistic framework that generates multiple plausible meshes aligned with images. This framework models the 3D virtual marker estimation as a conditional denoising process, enabling robust 3D mesh estimation. Our approaches surpass existing methods on three benchmark datasets, particularly demonstrating significant improvements on the SURREAL dataset, which features diverse body shapes. Additionally, VMarker-Pro excels in accurately modeling data distributions, significantly enhancing performance in occluded scenarios.
|


|
Abstract |
Paper |
Code |
Project page |
Video |
Bibtex
Estimating robot pose from RGB images is a crucial problem in computer vision and robotics. While previous methods have achieved promising performance, most of them presume full knowledge of robot internal states, e.g. ground-truth robot joint angles, which are not always available in real-world scenarios. On the other hand, existing approaches that estimate robot pose without joint state priors suffer from heavy computation burdens and thus cannot support real-time applications. This work addresses the urgent need for efficient robot pose estimation with unknown states. We propose an end-to-end pipeline for real-time, holistic robot pose estimation from a single RGB image, even in the absence of known robot states. Our method decomposes the problem into estimating camera-to-robot rotation, robot state parameters, keypoint locations, and root depth. We further design a corresponding neural network module for each task. This approach allows for learning multi-facet representations and facilitates sim-to-real transfer through self-supervised learning. Notably, our method achieves inference with a single feedforward, eliminating the need for costly test-time iterative optimization. As a result, it delivers a 12 times speed boost with state-of-the-art accuracy, enabling real-time holistic robot pose estimation for the first time.
|
|

|
Abstract |
Paper |
Code |
Project page |
Video |
Bibtex
Monocular 3D human mesh estimation is an ill-posed problem, characterized by inherent ambiguity and occlusion. While recent probabilistic methods propose generating multiple solutions, little attention is paid to obtaining high-quality estimates from them. To address this limitation, we introduce ScoreHypo, a versatile framework by first leveraging our novel HypoNet to generate multiple hypotheses, followed by employing a meticulously designed scorer, ScoreNet, to evaluate and select high-quality estimates. ScoreHypo formulates the estimation process as a reverse denoising process, where HypoNet produces a diverse set of plausible estimates that effectively align with the image cues. Subsequently, ScoreNet is employed to rigorously evaluate and rank these estimates based on their quality and finally identify superior ones. Experimental results demonstrate that HypoNet outperforms existing state-of-the-art probabilistic methods as a multi-hypothesis mesh estimator. Moreover, the estimates selected by ScoreNet significantly outperform random generation or simple averaging. Notably, the trained ScoreNet exhibits generalizability, as it can effectively score existing methods and significantly reduce their errors by more than 15%.
|
|
Abstract |
Paper |
Code |
Project page |
🤗 Live demo |
Bibtex
The advancing of human-scene interaction modeling confronts substantial challenges in the scarcity of high-quality data and advanced motion synthesis methods. Previous endeavors have been inadequate in offering sophisticated datasets that effectively tackle the dual challenges of scalability and data quality. In this work, we overcome these challenges by introducing TRUMANS (TRacking hUMan ActioNs in Scenes), a large-scale MoCap dataset created by efficiently and precisely replicating the synthetic scenes in the physical environment. TRUMANS, featuring the most extensive motion-captured human-scene interaction datasets thus far, comprises over 15 hours of diverse human behaviors, including concurrent interactions with dynamic and articulated objects, across 100 indoor scene configurations. It provides accurate pose sequences of both humans and objects, ensuring a high level of contact plausibility during the interaction. To further enhance adaptivity, we propose a data augmentation approach that automatically adapts collision-free and interaction-precise human motions. Leveraging the benefits of TRUMANS, we propose a novel approach that employs a diffusion-based autoregressive mechanism for the real-time generation of human-scene interaction sequences with arbitrary length. The efficacy of TRUMANS and our motion synthesis method is validated through extensive experimental results, surpassing all existing baselines in terms of quality and diversity. Notably, our method demonstrates superb zero-shot generalizability on existing 3D scene datasets (e.g., PROX, Replica, ScanNet, ScanNet++), capable of generating even more realistic motions than the ground-truth annotations on PROX. Our human study further indicates that our generated motions are almost indistinguishable from the original motion-captured sequences, highlighting their superior quality. Our dataset and model will be released for research purposes.
|
|
|
Abstract |
Paper |
Bibtex
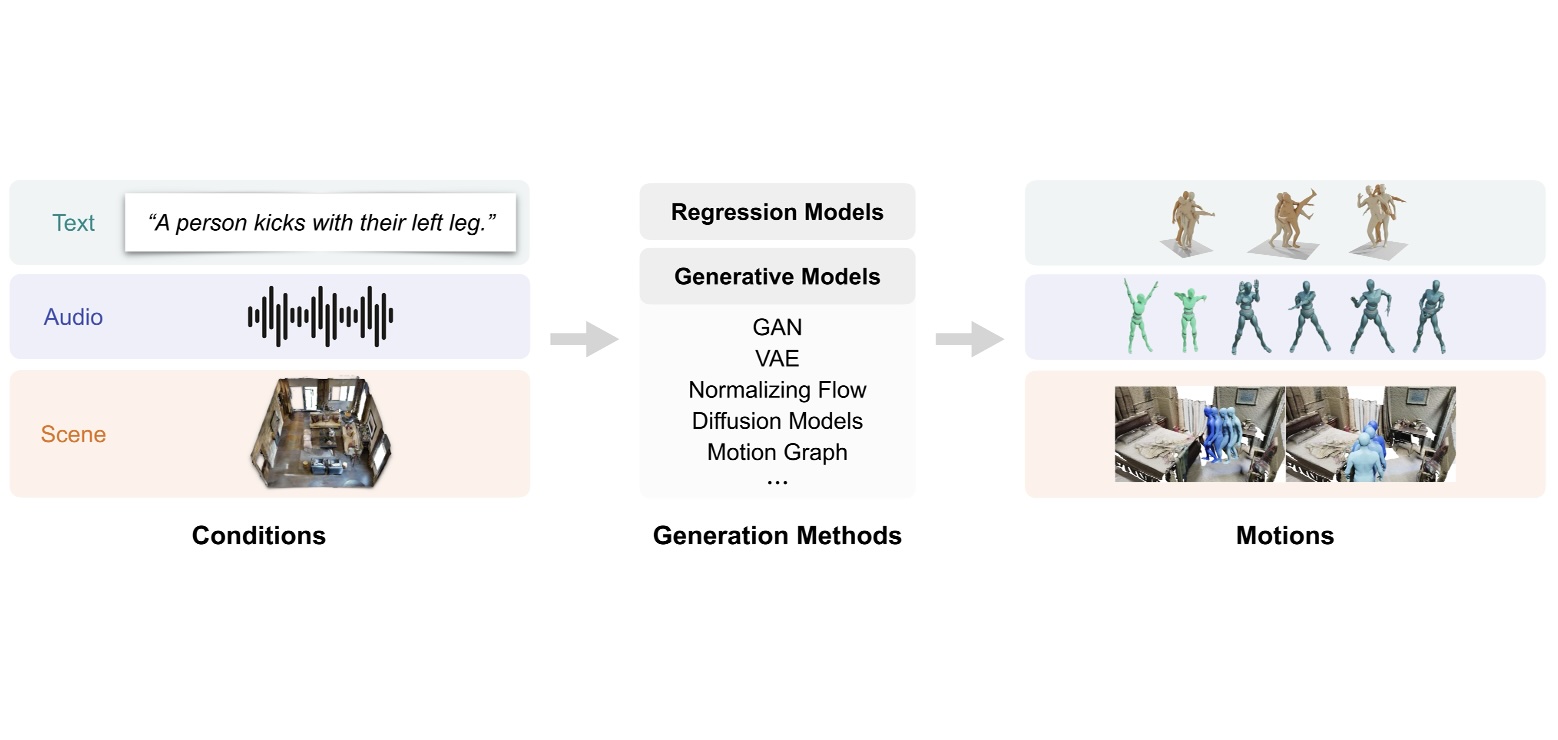
Human motion generation aims to generate natural human pose sequences and shows immense potential for real-world applications. Substantial progress has been made recently in motion data collection technologies and generation methods, laying the foundation for increasing interest in human motion generation. Most research within this field focuses on generating human motions based on conditional signals, such as text, audio, and scene contexts. While significant advancements have been made in recent years, the task continues to pose challenges due to the intricate nature of human motion and its implicit relationship with conditional signals. In this survey, we present a comprehensive literature review of human motion generation, which, to the best of our knowledge, is the first of its kind in this field. We begin by introducing the background of human motion and generative models, followed by an examination of representative methods for three mainstream sub-tasks: text-conditioned, audio-conditioned, and scene-conditioned human motion generation. Additionally, we provide an overview of common datasets and evaluation metrics. Lastly, we discuss open problems and outline potential future research directions. We hope that this survey could provide the community with a comprehensive glimpse of this rapidly evolving field and inspire novel ideas that address the outstanding challenges.
|



|
Abstract |
Paper |
Code |
Data |
Video |
Project page |
Bibtex
Understanding the behavior of non-human primates is crucial for improving animal welfare, modeling social behavior, and gaining insights into distinctively human and phylogenetically shared behaviors. However, the lack of datasets on non-human primate behavior hinders in-depth exploration of primate social interactions, posing challenges to research on our closest living relatives. To address these limitations, we present ChimpACT, a comprehensive dataset for quantifying the longitudinal behavior and social relations of chimpanzees within a social group. Spanning from 2015 to 2018, ChimpACT features videos of a group of over 20 chimpanzees residing at the Leipzig Zoo, Germany, with a particular focus on documenting the developmental trajectory of one young male, Azibo. ChimpACT is both comprehensive and challenging, consisting of 163 videos with a cumulative 160,500 frames, each richly annotated with detection, identification, pose estimation, and fine-grained spatiotemporal behavior labels. We benchmark representative methods of three tracks on ChimpACT: (i) tracking and identification, (ii) pose estimation, and (iii) spatiotemporal action detection of the chimpanzees. Our experiments reveal that ChimpACT offers ample opportunities for both devising new methods and adapting existing ones to solve fundamental computer vision tasks applied to chimpanzee groups, such as detection, pose estimation, and behavior analysis, ultimately deepening our comprehension of communication and sociality in non-human primates.
|
|

|
Abstract |
Paper |
Code |
Data |
Video |
Project page |
Bibtex
Humans exhibit a remarkable capacity for anticipating the actions of others and planning their own actions accordingly. In this study, we strive to replicate this ability by addressing the social motion prediction problem. We introduce a new benchmark, a novel formulation, and a cognition-inspired framework. We present Wusi, a 3D multi-person motion dataset under the context of team sports, which features intense and strategic human interactions and diverse pose distributions. By reformulating the problem from a multi-agent reinforcement learning perspective, we incorporate behavioral cloning and generative adversarial imitation learning to boost learning efficiency and generalization. Furthermore, we take into account the cognitive aspects of the human social action planning process and develop a cognitive hierarchy framework to predict strategic human social interactions. We conduct comprehensive experiments to validate the effectiveness of our proposed dataset and approach.
|
|
Abstract |
Paper |
Arxiv |
Code |
Project page |
Bibtex
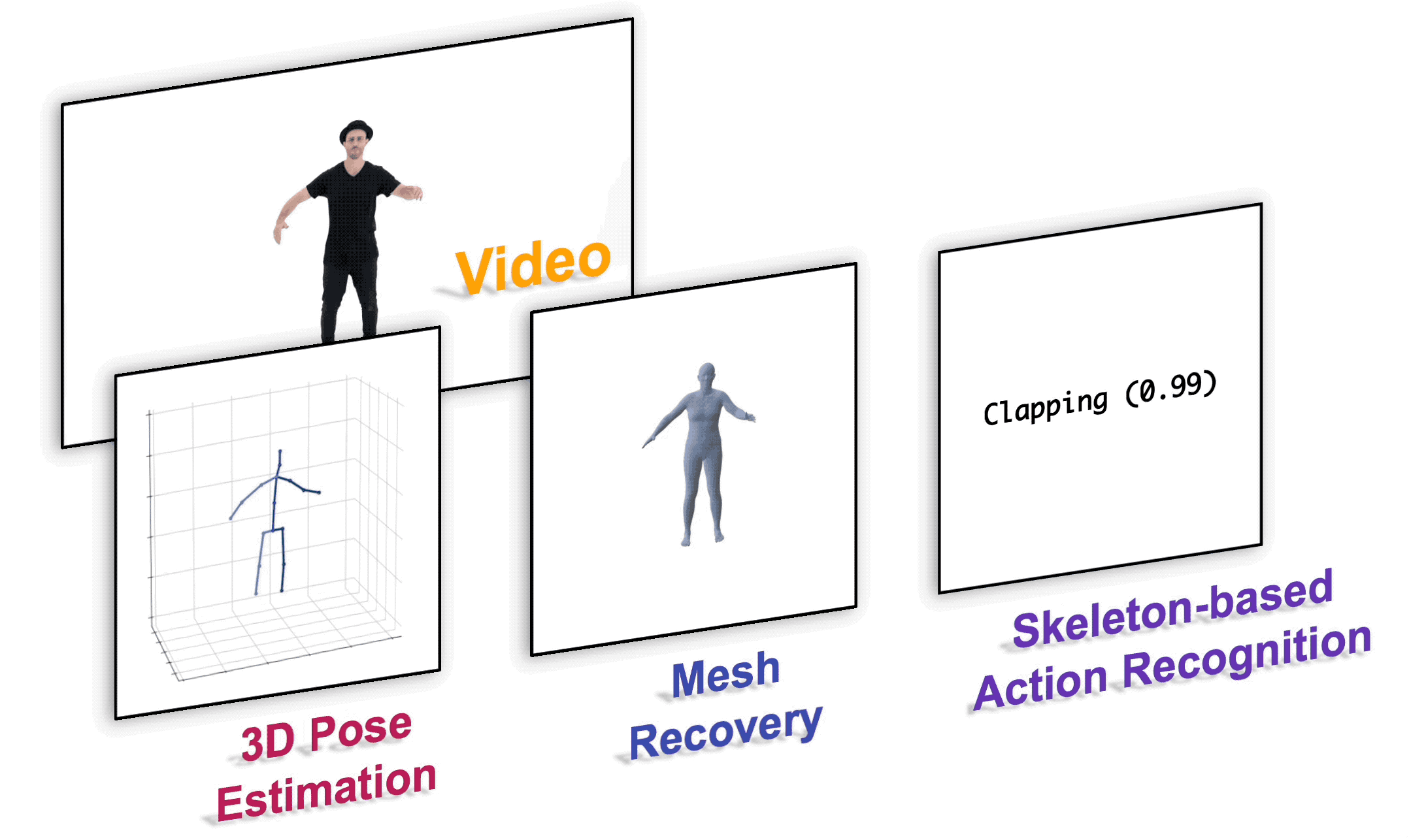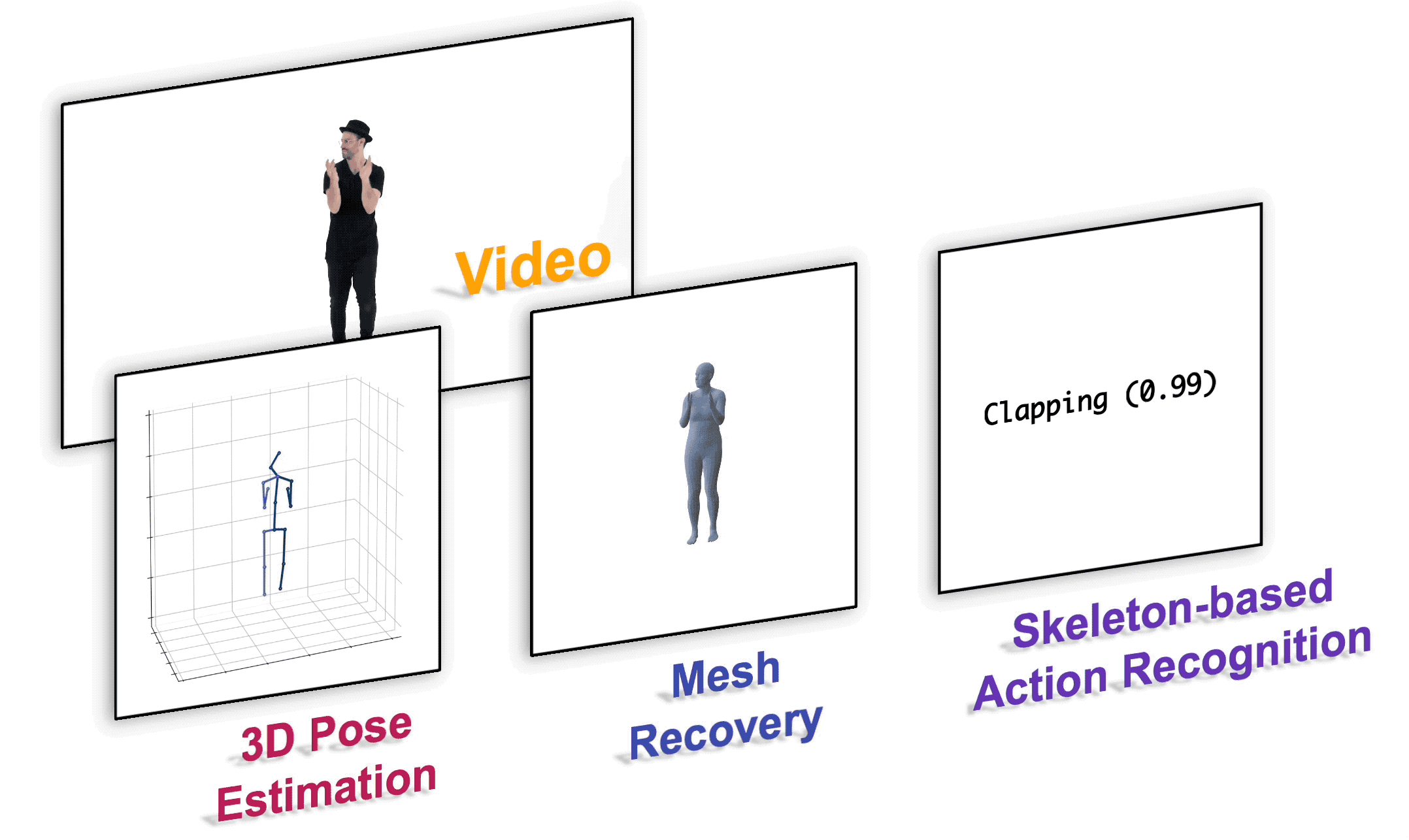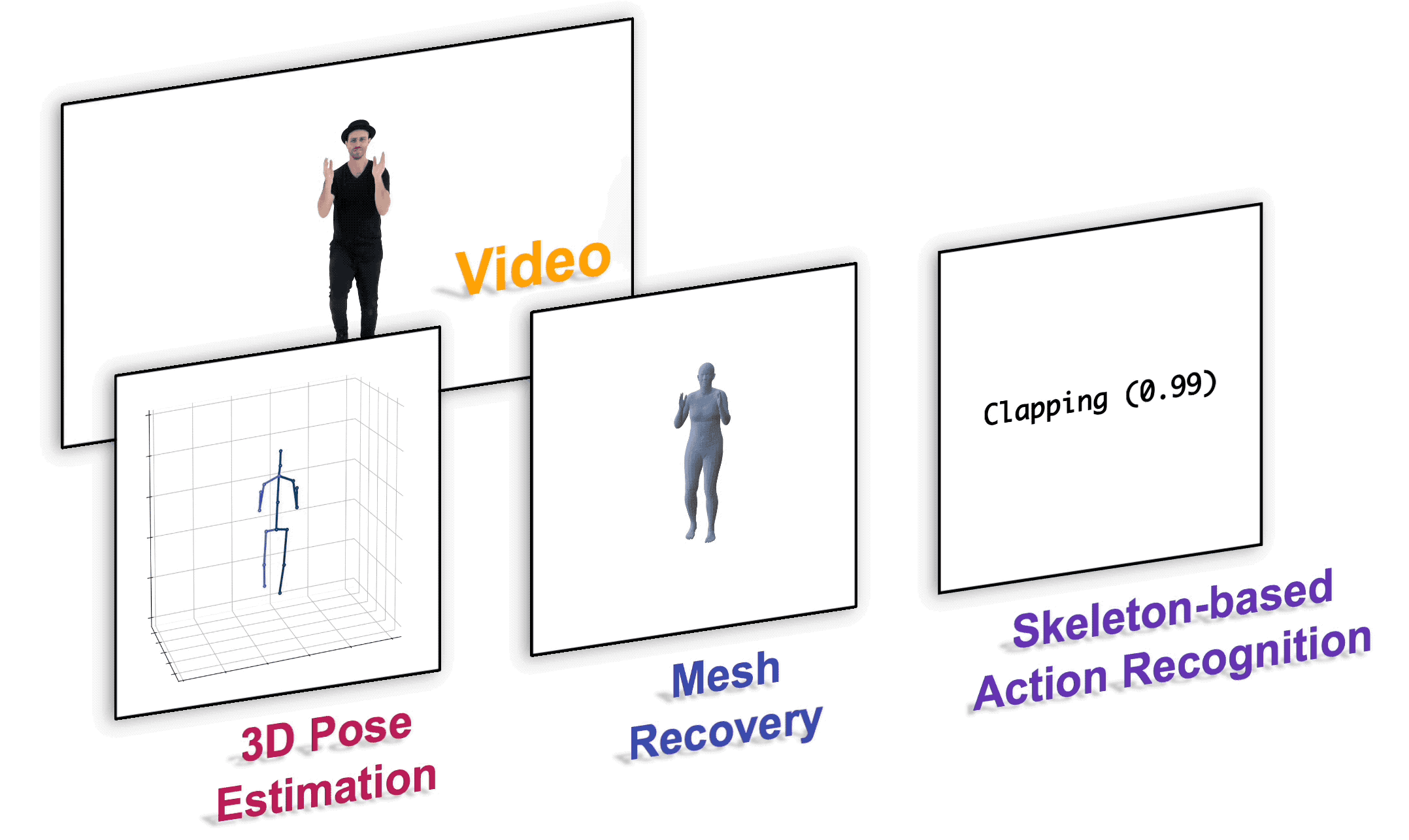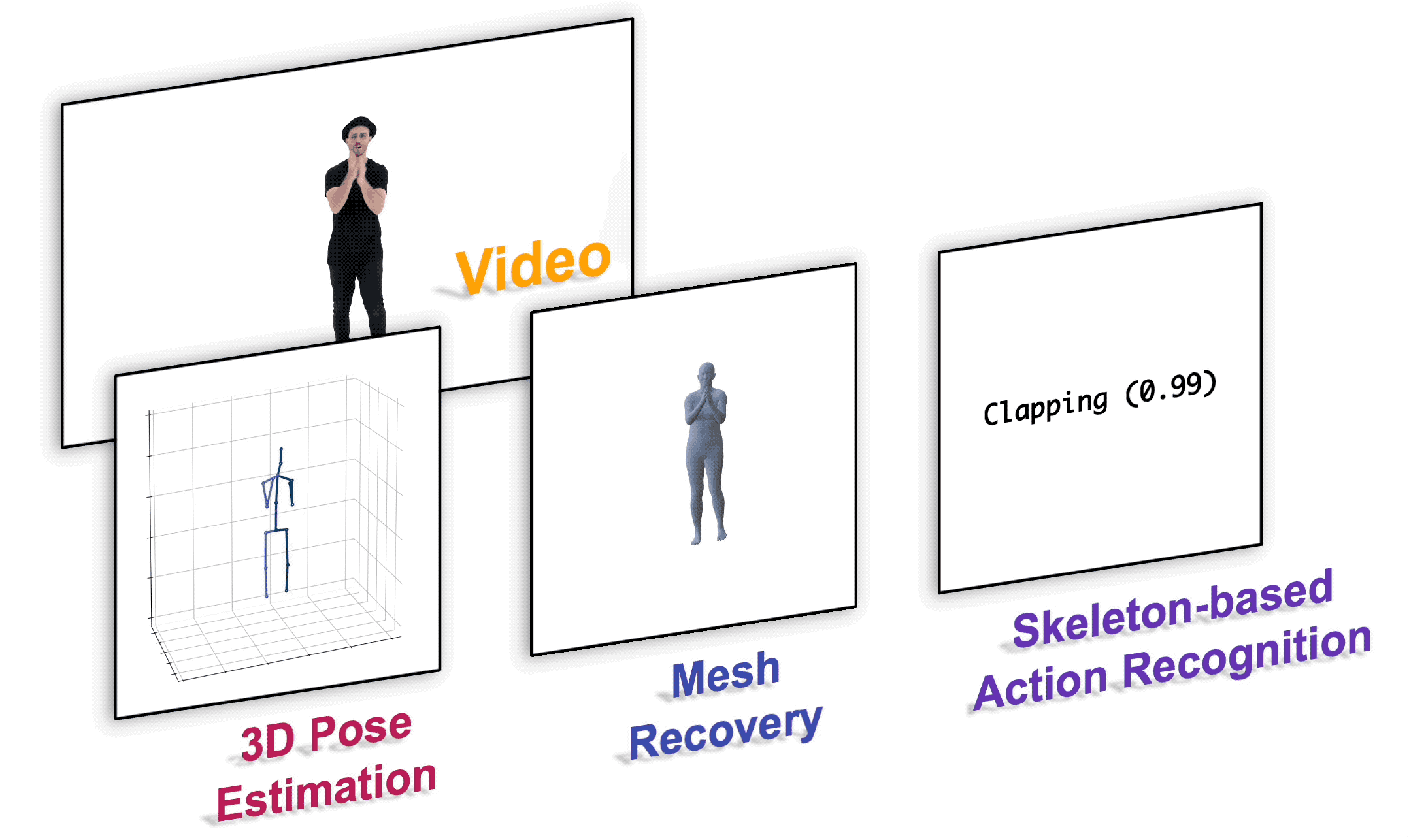
We present a unified perspective on tackling various human-centric video tasks by learning human motion representations from large-scale and heterogeneous data resources. Specifically, we propose a pretraining stage in which a motion encoder is trained to recover the underlying 3D motion from noisy partial 2D observations. The motion representations acquired in this way incorporate geometric, kinematic, and physical knowledge about human motion, which can be easily transferred to multiple downstream tasks. We implement the motion encoder with a Dual-stream Spatio-temporal Transformer (DSTformer) neural network. It could capture long-range spatio-temporal relationships among the skeletal joints comprehensively and adaptively, exemplified by the lowest 3D pose estimation error so far when trained from scratch. Furthermore, our proposed framework achieves state-of-the-art performance on all three downstream tasks by simply finetuning the pretrained motion encoder with a simple regression head (1-2 layers), which demonstrates the versatility of the learned motion representations.
|
|
Abstract |
Paper |
Supplementary |
Code |
Project page |
Bibtex
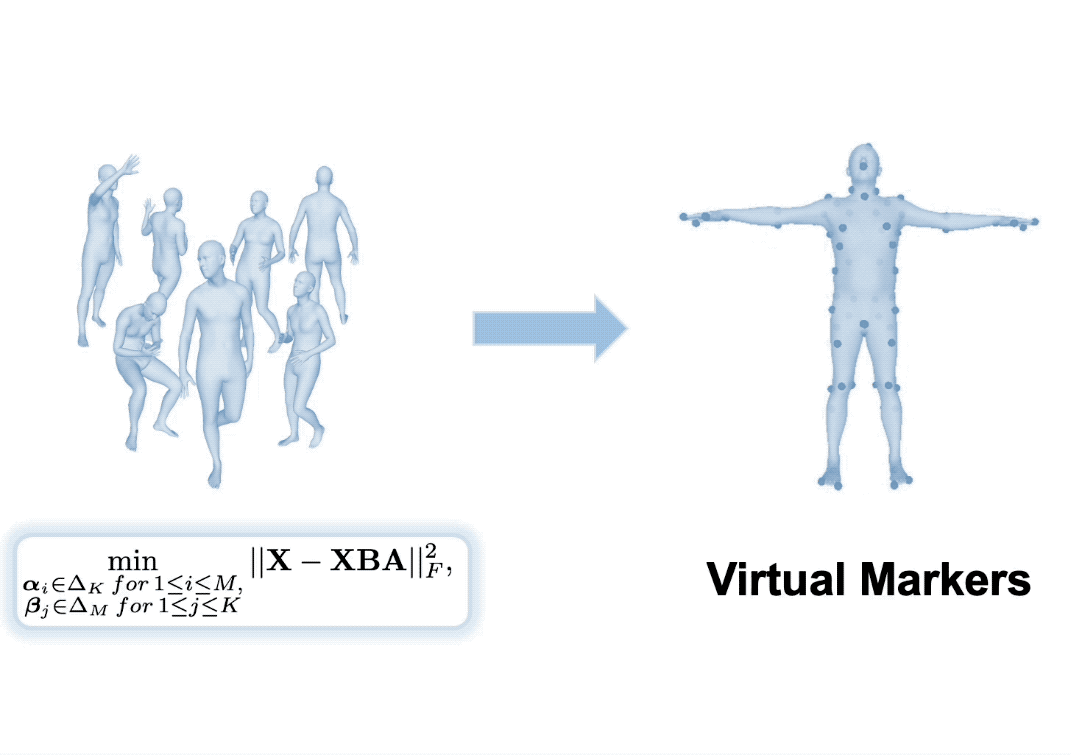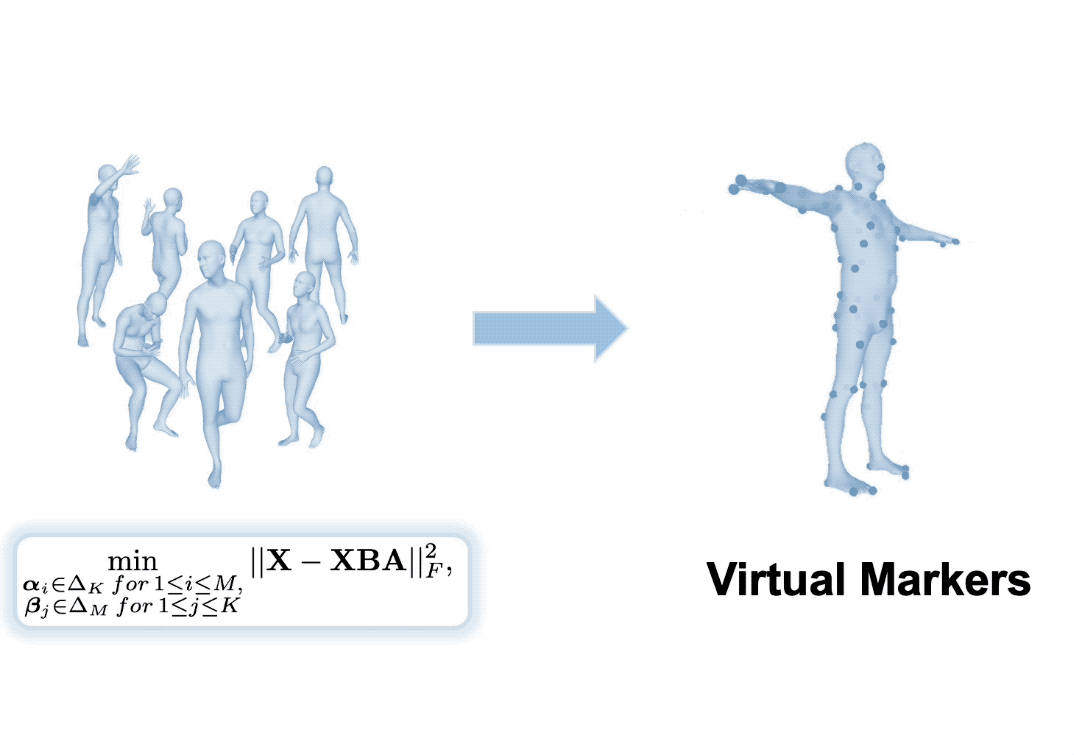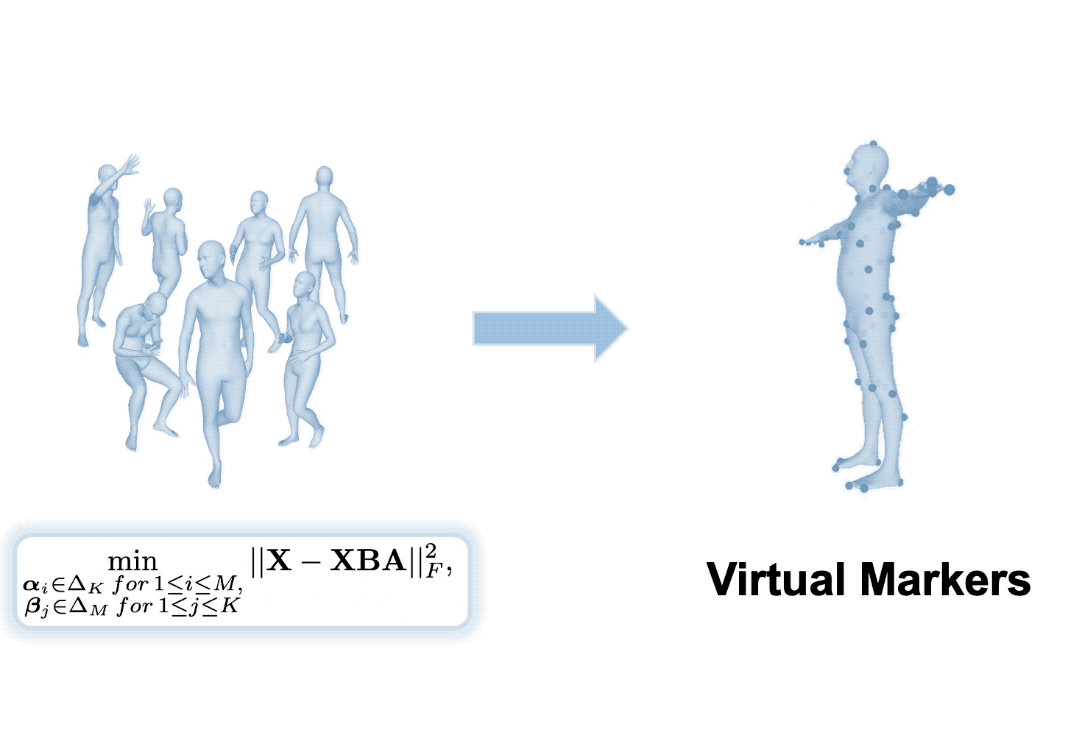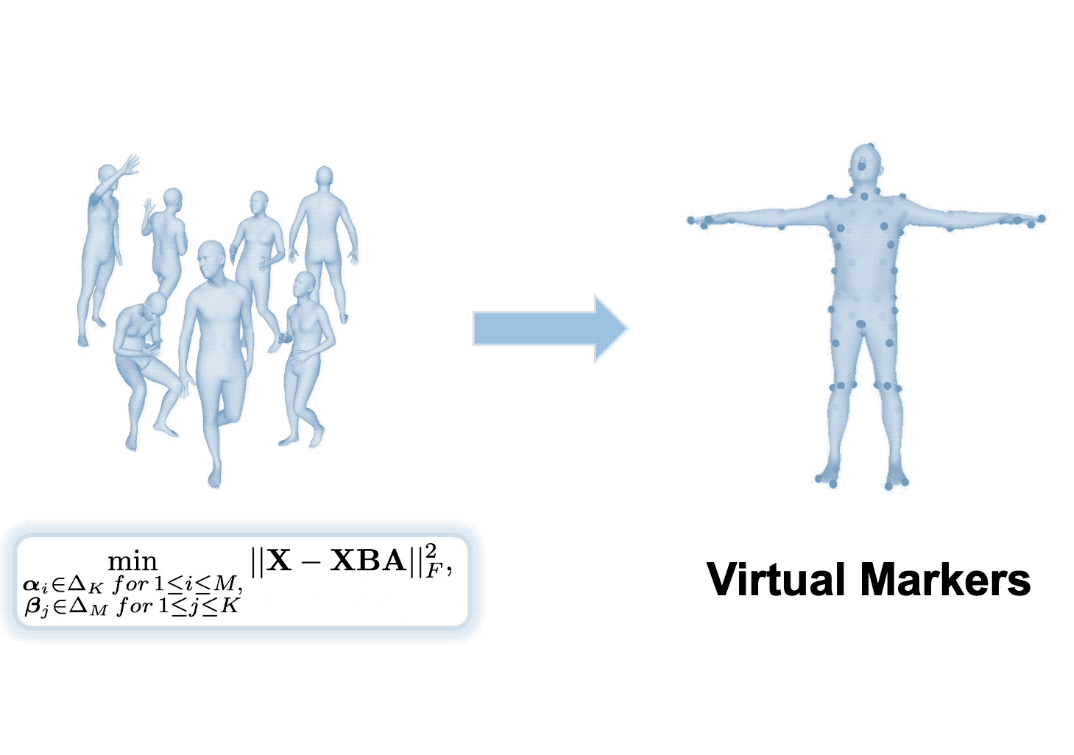
Inspired by the success of volumetric 3D pose estimation, some recent human mesh estimators propose to estimate 3D skeletons as intermediate representations, from which, the dense 3D meshes are regressed by exploiting the mesh topology. However, body shape information is lost in extracting skeletons, leading to mediocre performance. The advanced motion capture systems solve the problem by placing dense physical markers on the body surface, which allows to extract realistic meshes from their non-rigid motions. However, they cannot be applied to wild images without markers. In this work, we present an intermediate representation, named virtual markers, which learns 64 landmark keypoints on the body surface based on the large-scale mocap data in a generative style, mimicking the effects of physical markers. The virtual markers can be accurately detected from wild images and can reconstruct the intact meshes with realistic shapes by simple interpolation. Our approach outperforms the state-of-the-art methods on three datasets. In particular, it surpasses the existing methods by a notable margin on the SURREAL dataset, which has diverse body shapes.
|
|
Abstract |
Paper |
Supplementary |
Code |
Project page |
Bibtex
Learning 3D human pose prior is essential to human-centered AI. Here, we present GFPose, a versatile framework to model plausible 3D human poses for various applications. At the core of GFPose is a time-dependent score network, which estimates the gradient on each body joint and progressively denoises the perturbed 3D human pose to match a given task specification. During the denoising process, GFPose implicitly incorporates pose priors in gradients and unifies various discriminative and generative tasks in an elegant framework. Despite the simplicity, GFPose demonstrates great potential in several downstream tasks. Our experiments empirically show that 1) as a multi-hypothesis pose estimator, GFPose outperforms existing SOTAs by 20% on Human3.6M dataset. 2) as a single-hypothesis pose estimator, GFPose achieves comparable results to deterministic SOTAs, even with a vanilla backbone. 3) GFPose is able to produce diverse and realistic samples in pose denoising, completion and generation tasks.
|






|
Abstract |
Paper |
Code |
Bibtex
We present an approach for 3D human pose estimation from monocular images. The approach consists of two steps: it first estimates a 2D pose from an image and then estimates the corresponding 3D pose. This paper focuses on the second step. Graph convolutional network (GCN) has recently become the de facto standard for human pose related tasks such as action recognition. However, in this work, we show that GCN has critical limitations when it is used for 3D pose estimation due to the inherent weight sharing scheme. The limitations are clearly exposed through a novel reformulation of GCN, in which both GCN and Fully Connected Network (FCN) are its special cases. In addition, on top of the formulation, we present locally connected network (LCN) to overcome the limitations of GCN by allocating dedicated rather than shared filters for different joints. We jointly train the LCN network with a 2D pose estimator such that it can handle inaccurate 2D poses. We evaluate our approach on two benchmark datasets and observe that LCN outperforms GCN, FCN, and the state-of-the-art methods by a large margin. More importantly, it demonstrates strong cross-dataset generalization ability because of sparse connections among body joints.
|
|
Abstract |
Paper |
Code |
Bibtex
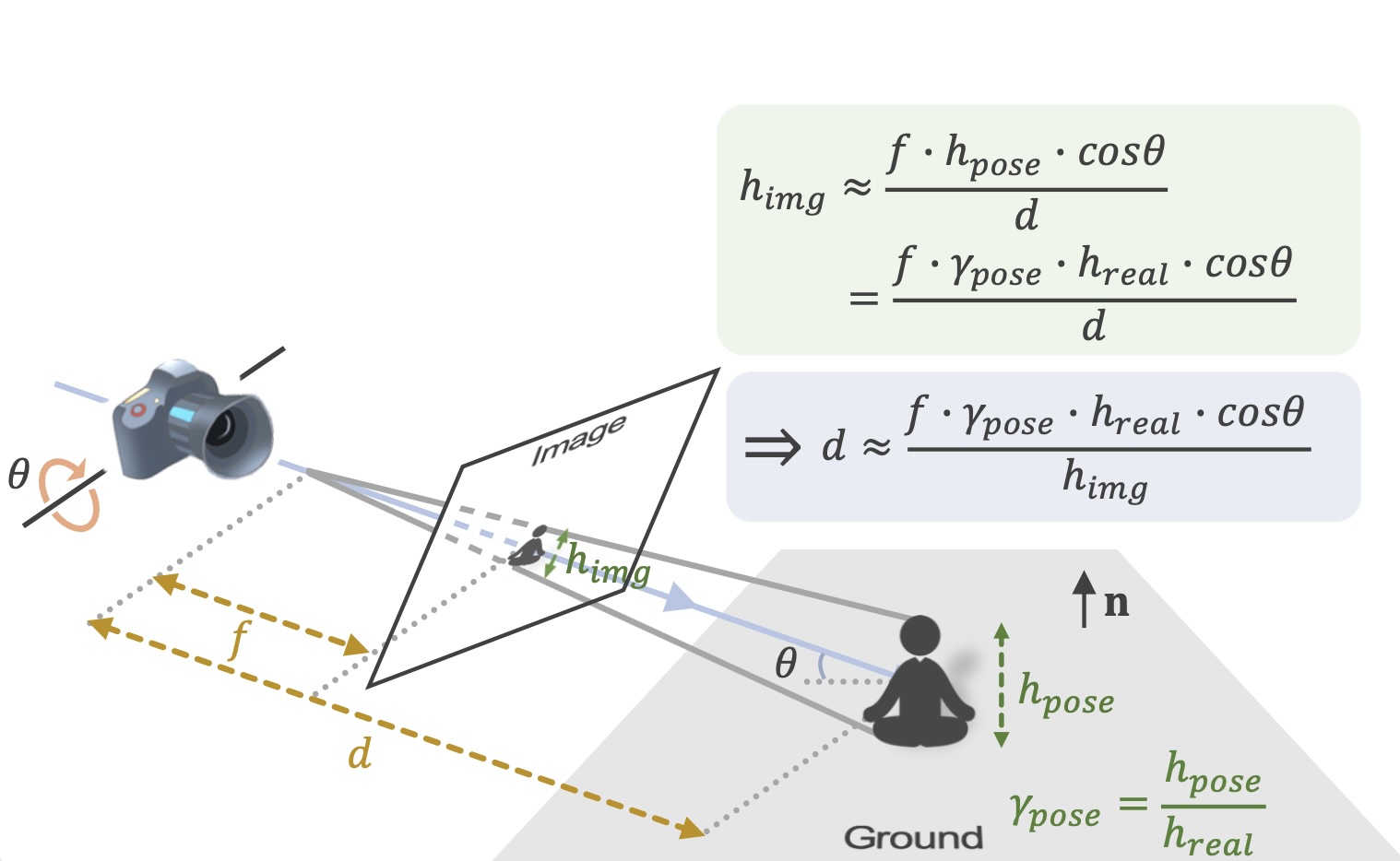
While monocular 3D pose estimation seems to have achieved very accurate results on the public datasets, their generalization ability is largely overlooked. In this work, we perform a systematic evaluation of the existing methods and find that they get notably larger errors when tested on different cameras, human poses and appearance. To address the problem, we introduce VirtualPose, a two-stage learning framework to exploit the hidden “free lunch” specific to this task, i.e.generating infinite number of poses and cameras for training models at no cost. To that end, the first stage transforms images to abstract geometry representations (AGR), and then the second maps them to 3D poses. It addresses the generalization issue from two aspects: (1) the first stage can be trained on diverse 2D datasets to reduce the risk of over-fitting to limited appearance; (2) the second stage can be trained on diverse AGR synthesized from a large number of virtual cameras and poses. It outperforms the SOTA methods without using any paired images and 3D poses from the benchmarks, which paves the way for practical applications.
|

|
Abstract |
Paper |
Code |
Bibtex
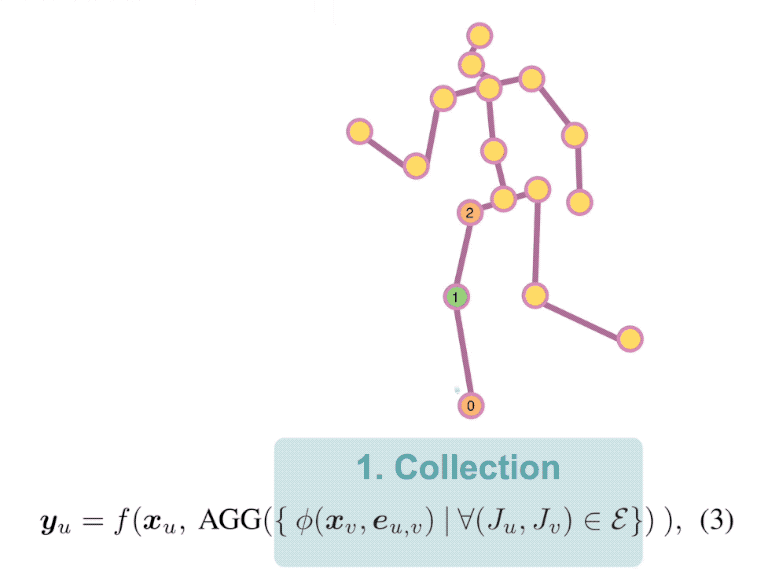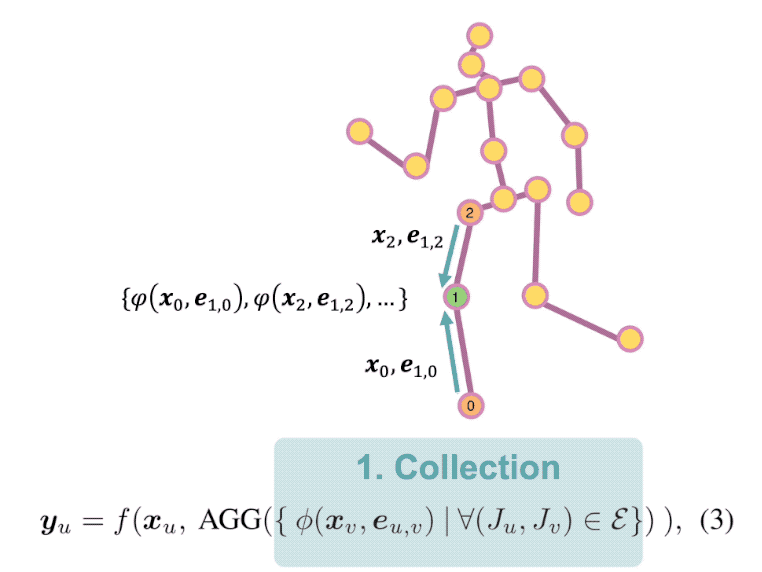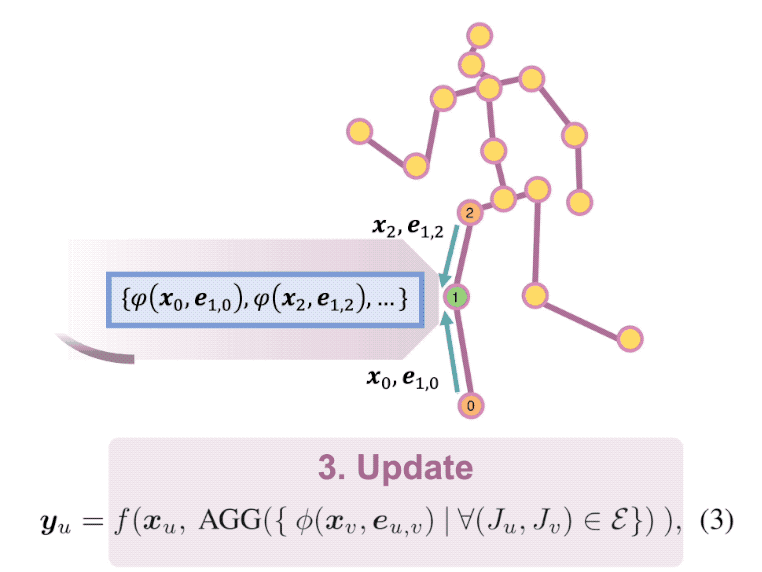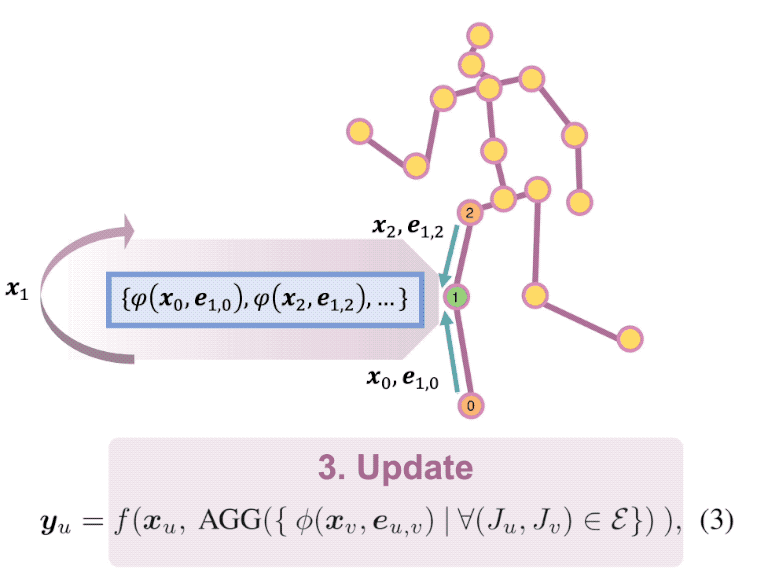
Estimating 3D human pose from a single image suffers from severe ambiguity since multiple 3D joint configurations may have the same 2D projection. The state-of-the-art methods often rely on context modeling methods such as pictorial structure model (PSM) or graph neural network (GNN) to reduce ambiguity. However, there is no study that rigorously compares them side by side. So we first present a general formula for context modeling in which both PSM and GNN are its special cases. By comparing the two methods, we found that the end-to-end training scheme in GNN and the limb length constraints in PSM are two complementary factors to improve results. To combine their advantages, we propose ContextPose based on attention mechanism that allows enforcing soft limb length constraints in a deep network. The approach effectively reduces the chance of getting absurd 3D pose estimates with incorrect limb lengths and achieves state-of-the-art results on two benchmark datasets. More importantly, the introduction of limb length constraints into deep networks enables the approach to achieve much better generalization performance.
|

|
Abstract |
Paper |
Code |
Bibtex
A human pose is naturally represented as a graph where the joints are the nodes and the bones are the edges. So it is natural to apply Graph Convolutional Network (GCN) to estimate 3D poses from 2D poses. In this work, we propose a generic formulation where both GCN and Fully Connected Network (FCN) are its special cases. From this formulation, we discover that GCN has limited representation power when used for estimating 3D poses. We overcome the limitation by introducing Locally Connected Network (LCN) which is naturally implemented by this generic formulation. It notably improves the representation capability over GCN. In addition, since every joint is only connected to a few joints in its neighborhood, it has strong generalization power. The experiments on public datasets show it: (1) outperforms the state-of-the-arts; (2) is less data hungry than alternative models; (3) generalizes well to unseen actions and datasets.
|

Academic ServicesJournal Reviewer: IEEE TPAMI, IJCV, IEEE TMM, IEEE Internet of Things Journal (IOTJ) Conference Reviewer: CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, AAAI, SIGGRAPH Asia, CAD/Graphics Workshop Organizer: CVPR 2025 5th CV4Animals Workshop , CVPR 2026 6th CV4Animals Workshop |
TeachingComputational Vision (TA) Fall 2019 Machine Learning for Time Series Analysis – Statistical Models and Deep Learning (TA) Summer 2018 Computation, Economics and Data Science (TA) Summer 2018 |
Co-mentoringI am fortunate to have the opportunity to work with a few talented and highly motivated junior students (ordered by year): · Hang Ye (2022-Now) now PhD student @ PKU, advised by Prof. Yizhou Wang · Jason Qin (2022-2023) now PhD student @ Stony Brook, advised by Prof. Dimitris Samaras · Yuan Xu (2022-Now) now PhD student @ PKU, advised by Prof. Yizhou Wang · Chi Su (2023-Now) now PhD student @ PKU, advised by Prof. Yizhou Wang · Shikun Ban (2022-2024) now master student @ CMU · Yutang Lin (2024-Now) undergraduate @ PKU · Yizhe Cheng (2025-Now) undergraduate @ PKU · Chunxun Tian (2025-Now) undergraduate @ PKU |